Using Random Forest to build a stock portfolio
 Photo by rawpixel on Unsplash
Photo by rawpixel on Unsplash
Overview
I am building a strategy for stock market that will maximize my portfolio returns. My portfolio will have only one stock symbol at a time (JPM). The goal is to learn from the market in the past using technical analysis and then take intelligent steps in the future to increase the portfolio returns. For learning the trends of a stock I have used Random Forest learner. This learner is assisted by 3 Technical analysis indicators that will guide it to learn important trends in the market. This learner replicates the technical analysis done by humans for predicting the stock market and taking intelligent decisions to LONG and SHORT stocks.
Assumptions and Pre-requisites
Following gives a description of the function of each of the imports
util.get_data()
Provides CSV files with stock market data for multiple stock symbols in US stock market
marketsimcode.marketsim()
Provides a code to simulate market. This function accepts orders which contain stock orders for a particular symbol and a particular date, initial investment as “start_val”, broker commission as “commission” and impact as “impact”.
RTLearner
This is a Random Decision Tree Learner with Feature selection at every node as a Random function
BagLearner
This learner calls provided learner using Bagging. We can input bag size
The stock symbols
The stock symbols are words which represent the stock name on US stock market. Also each of the symbols must be present inside the data folder. Stock symbol for testing and training: JPM
In sample Period
The in-sample period is January 1, 2008 to December 31, 2009.
Out sample Period
The out-of-sample/testing period is January 1, 2010 to December 31, 2011.
initial amount
Starting cash is $100,000.
commission
commission is the fixed amount in dollars charged for each transaction (both entry and exit)
impact
Market impact: For each trade that I execute, assume that the stock price moves against me according to the impact parameter. So, if I am buying, assume the price goes up (e.g., rises 50 bps) before your purchase. Similarly, if selling, assume the price drops (e.g., falls 50 bps) before the sale. For simplicity treat the market impact penalty as a deduction from my cash balance. Fixed value of 0.005%
Positions
Allowable positions are: 1000 shares long, 1000 shares short, 0 shares
Technical Indicators
Technical Indicators are heuristics used to analyze the stock market and its trends using historical data and trading volume. I have used the same technical indicators that I used for Manual Strategy, i.e. Simple Moving Average, Bollinger Bands and Momentum
Random Forest
For solving this problem I used Random Forest algorithm to train on the In Sample JPM data. For this Random Forest I used a Random Decision Tree with leaf size as 5 and bagging with number of bags = 30. Bagging was used to reduce the Overfitting often introduced due to smaller leaf sizesA random forest is a bagged random decision tree. A decision tree is supervised learning method used in classification and regression. In our case we will use a regression tree. In a decision tree, the training data is divided among multiple nodes based on feature values. These features are located in the nodes of the tree. There can be multiple features for a data point. Based on the feature values the training sample
Bootstrap Aggregation (Bagging)
It is also called an ensemble learning and is a way to combine two or more learning models together. It is advantageous for reducing overfitting. The basic idea is to create number of bags of data randomly selected with replacement. Replacement is to avoid repetition of same data points. Each of these bags is used as training set for the respective model. Since there are multiple models they will generate multiple predictions. Hence to select the correct prediction we take Mean or Mode of the prediction.
Training a Random decision tree
This is nothing but building the decision tree using the training samples. Each training sample has multiple features. While building the decision tree we need to decide the feature that will be useful for splitting the data samples. In a Random Decision tree, I am selecting the feature randomly. However in a normal decision tree there are various ways to select the feature like Correlation Coefficient, Gini impurity etc.
Trading Problem as a learning Problem
Before starting the learning process, we need to map the trading problem as an ML problem. For transforming this problem into a learning problem, a data pre-processing layer is used in the Strategy Learner to prepare training and testing data.
Prepare Training and Testing data
Here, I calculated the indicators values for a provided timeframe for a particular symbol. For each of these indicator data-frames, I used forward filling and backward filling since all my indicators are window based. This eliminated NaN values. For Training and Testing data I used indicator data-frames as X data for In-sample and Out-sample period respectively. After that I kept the raw values for X data as they were sufficient to understand trends in the data for Random Forest. For discretizing the Y data, I used the following method that converted raw stock values into [0,-1,1] based on various hyper-parameters. Y Train To prepare Y values in training phase I had to calculate market returns as follows in the In-Sample period for JPM
returns=(symbol_df[symbol].iloc[i+N]/symbol_df[symbol].iloc[i])-1
if (returns > (YBUY+impact)):
#Price Goes up later by 20%, then BUY if not already bought. #LONG
train_y.append(1)
elif (returns < (YSELL-impact)):
#Price Goes down later by 20%, then SELL. #SHORT
train_y.append(-1)
is_holding=False
else:
train_y.append(0).
Here I used N=5 as 5 days future peeking window, YBUY=0.02 and YSELL=-0.02 meaning 2% returns. If returns (Y[t]) were greater or smaller, then I took a LONG or SHORT position respectively else I followed the older position. Also, I included impact into my calculation because it represents true returns expected. Finally, I converted everything into Numpy for better performance.
Results
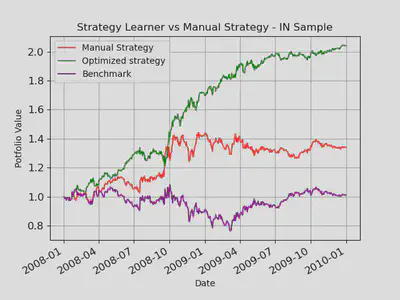
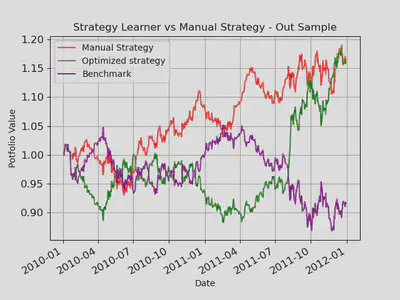
Experiment 1
Experiment 1 was performed to compare Manual Strategy with Strategy Learner for In Sample and Out Sample Data of JPM stock. In this experiment I used the above-mentioned Manual Strategy using 3 indicators and Strategy Learner using the same indicators with a Bagged Random Decision Tree. I trained the decision tree with in-sample data and queried it twice, for In Sample and Out Sample period. As seen in the table and graphs, my strategy learner could beat the manual strategy every time for in-sample data. Sometimes, it could also beat the manual strategy for the out-sample data. I believe this is because I used bagging and a cross validation set. The cum-returns, final value and mean-returns are higher than manual and benchmark. I expect these results every time with In-sample data because a Random Forest has the tendency to specialize on the training data. The graphs and table show that Strategy Learner performed significantly better in the in-sample period because I used leaf size 5 to train the Random Forest and it knew the market trends in the training phase.
Tabular Results
| Stats | In Sample | Out Sample | ||||
|---|---|---|---|---|---|---|
| Manual Strategy | Strategy Learner | Bench-mark | Manual Strategy | Strategy Learner | Bench-mark | |
| Cumulative Ret | 0.340866 | 1.211751 | 0.012225 | 0.164599 | 0.225681 | -0.083678 |
| STD of Daily Ret | 0.012711 | 0.008501 | 0.017041 | 0.007356 | 0.009401 | 0.008500 |
| Mean Daily Ret | 0.000679 | 0.002076 | 0.000168 | 0.000338 | 0.001592 | -0.000137 |
| Final Value | $133,793 | $220,739 | $101,017 | $116,230 | $122,326 | $91,435 |
Graphical Results
Experiment 2
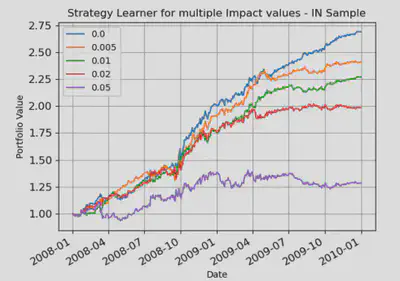
In this experiment I tested multiple impact values with the strategy learner and compared various statistics like Cumulative Returns, STD of Daily Returns, Mean Daily Returns. I could observe that if impact increases then the cumulative returns and mean Daily returns decrease and if impact remains low then they increase. This is because I included impact in the learning of Bagged Random DT. The impact was used to decide a BUY or SELL along with several other hyperparameters. If impact value increases, then the future returns will decrease and hence the learner prefers lower impact to increase future returns. That’s the reason of higher cumulative returns of the portfolio for lower impact values.
Graphical Results